Táblafelismerés Mesterséges Inteligenciával
Projektem egy ma is releváns témához kapcsolódik: a biztonságosabb autózáshoz, az önvezető autókhoz, illetve a mesterséges intelligenciához.
Célja: A közlekedési táblák automatikus, pontos felismerése, értelmezése.
Miért jó nekünk?
Sajnos a vezető figyelme egyre gyakrabban túlterhelődik, s mivel az autóvezetők koncentrációját egyre több zavaró tényező befolyásolja, szükségessé válik a valóban fontos információ kiemelése, például az éppen aktuális sebességkorlátozás. Szerencsére a technika rohamos fejlődésével, a számítógépek méretének csökkenésével, egyre több lehetőségünk van táblafelismerő rendszerek megvalósítására. Napjainkban már egyre több, új autóba kerül ilyen rendszer, azonban személyes tapasztalatom, hogy eléggé lassúak és pontatlanok. Gyakran olyan táblákat ismernek fel, melyek nincsenek az úton.
Ezzel szemben az én rendszerem, egy mesterséges intelligencián alapuló táblafelismerő rendszer, mely 95%-os pontosságal képes felismerni a táblákat.
Hogyan működik?
Egy számítógép a hozzá csatlakoztatott kamera képét folyamatosan, valós időben analizálja egy mesterséges intelligencia segítségével, mely szintén az én alkotásom. (Videoval szemléltetve)
De mi is az a mesterséges intelligencia? A mesterséges intelligencia (röviden Mi- angolul: Ai) egy gép, emberhez hasonlatos képességet jelent, mint például a tanulás, a helyzetfelismerés és a kreativitás. Mindennapi életünk során is kapcsolatba kerülünk ilyen algoritmusokkal, úgy a termelői szférában, mint az otthonunkban. Például az interneten történő kereséskor, a keresőmotorok böngészési előzményeinkből, oldalakon töltött időinkről, statisztikát készítenek melyek felhasználásával a lehető legrelevánsabb találatot részesítik előnyben.
A kész algoritmus demója ide kattintva kipróbálható! (legalább 4 magos, erősebb processszor ajánlott)
A fenti videón a kész mesterséges inteligencia működés közben látható. Megfigyelhető hogy az észlelési idő csupán pár miliszekundum, továbbá hogy a különböző szögekben látható táblák sem okoznak problémát az algoritmusnak.
Hogyan készült?
A mesterséges intelligencia megalkotásához, elsőként, képeket kell készíteni az adott tárgyról, amit szeretnénk, hogy később felismerjen, “A kevesebb néha több” mondás itt is alkalmazható. Jobb minőségű képekkel, jobb eredményt lehet elérni. Fontos, hogy a felismerni kívánt tárgyakat, több szögből, különböző háttérrel fotózzuk, így megkönnyítjuk az algoritmus haználatát a különböző környezetekben.




A képek elkészítését követően a szortírozás következik. Az életlen, bemozdult, pixeles képeket nem ajánlatos felhasználni. Amennyiben megvan a minőségi képhalmazunk, kezdődhet a “felcímkézés”. Ez az a folyamat, amikor az algoritmusunknak megmutatjuk, hogy a képeken pontosan mit ismerjen fel. Ehhez a “labelimg” nevezetű programot használtam, mely egy .xml file-ba menti el a bejelölt tárgyak pozícióját. A következő videó ezt a lépést mutatja be.
Az előző lépésben létrehoztuk az adathalmazunkat, mely jelenleg képeket, és xml file-okat tartalmaz. A tényleges algoritmus létrehozásához azonban, szükségünk lesz a TensorFlow névre hallgató könyvtár-csomagra. Ez egy ingyenes és nyílt forráskódú szoftverkönyvtár, a gépi tanuláshoz, és a mesterséges intelligenciához. Számos feladatban használható, de különös hangsúlyt fektet a mély, neurális hálózatok képzésére és következtetésére. Az adathalmazunkat elosztjuk 80 és 20 százalékos arányban, A képek nagyobb részét (80%) egy „train” nevezetű mappába helyezzük. Ebből a mappából képes az algoritmus tanulni. A 20%-os részt egy „teszt” nevezetű mappába helyezzük. A teszt mappában lévő képekkel az algoritmus, folyamatosan ellenőrzi önmagát, hogy hol tart a tanulási folyamatban, szükséges-e még fejlődnie, vagy sem.
Ezt követően, választunk egy, már előre elkészített modellt, melyről az algoritmusunk, mintázni fogja önmagát. E modellekből, kizárólag a konfigurációra van szükség, mivel a pontosságukat, és a gyorsaságukat ez határozza meg. Érdemes szakemberek által elkészített konfigurációra alapozni, és azt módosítani… Fontos megjegyezni; mivel ezek a modellek nyílt forráskódúak GPL (General Public License) felhasználásával szabadon módosíthatjuk őket. A teljes konfiglista megtekinthető: GitHub
A konfigurációk módosítása után elindíthatjuk az algoritmus tanulását, ami automatikusan leáll, amikor elkészült. A folyamathoz azonban szükségünk lesz egy CUDA kompatibilis videókártyára. A tanulási folyamat alatt folyamatosan ellenőrizhetjük, hogy milyen fejlett az algoritmus a „TensorBorad” nevezetű alkalmazással. Azonban nem szükséges a tanulási idő egésze alatt a gép mellett lennünk, hiszen ennél a módszernél a tanulásba nem tudunk beleszólni. A tanulási folyamat előtt létrehozott konfigurációkkak lehet ugyan játszadozni, ám, amint elindítjuk a tanulást, sem adathalmazt, sem a konfigurációt nem módosíthatjuk.
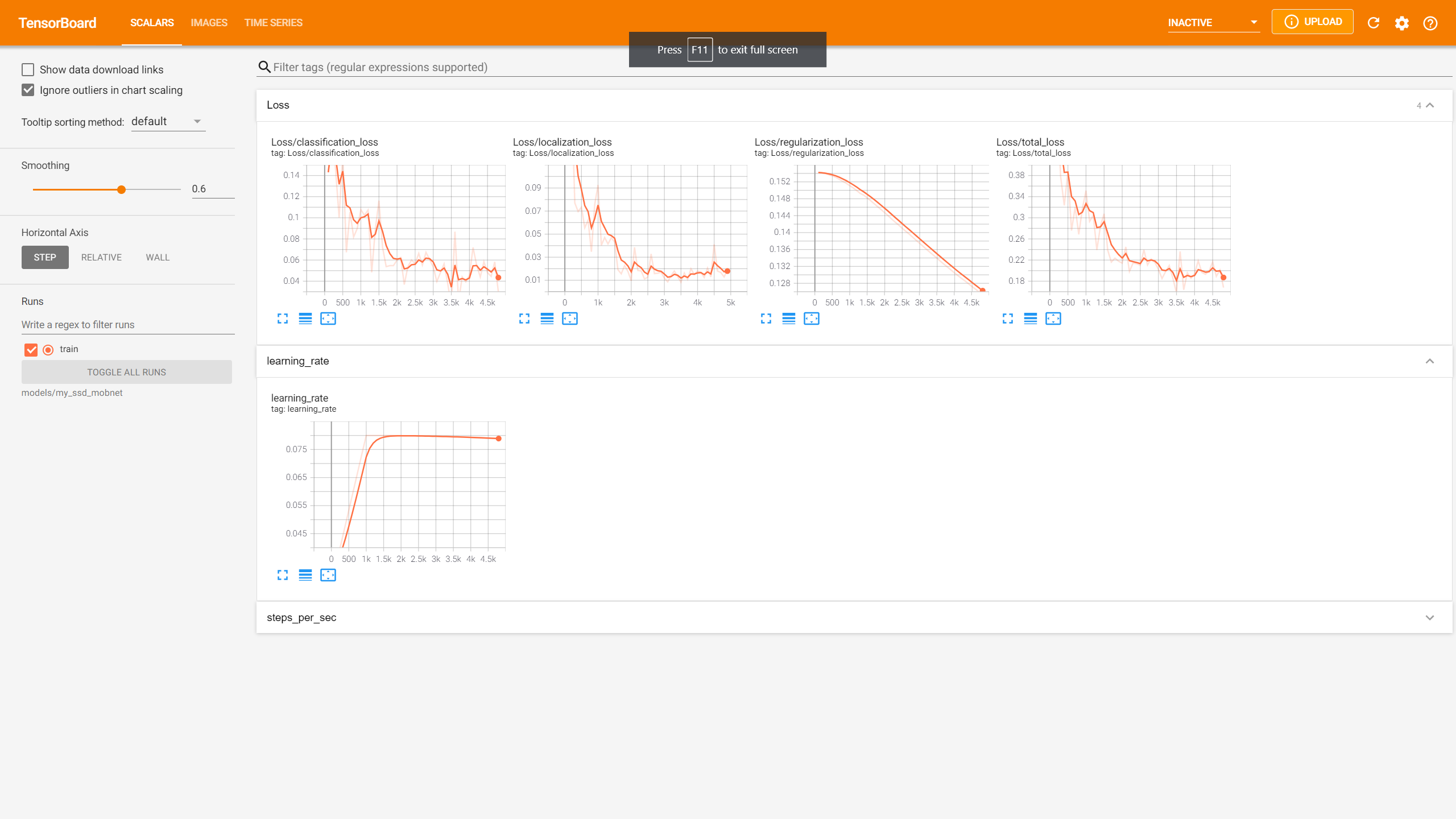
A fenti képen a TensorBoard nevezetű alkalmazás látható.A legfontosabb statisztika számunkra a bal felső grafikon, amely a tanulási lépések számát mutatja az X tengelyen (jelen esetben 4500-adik lépés), az Y tengelyen pedig a veszteségnek nevezett értéket látjuk. Ez az érték jelzi, hogy mennyire hatékony az algoritmusunk. Minél jobban megközelíti az Y tengely értéke a nullát, annál jobb.
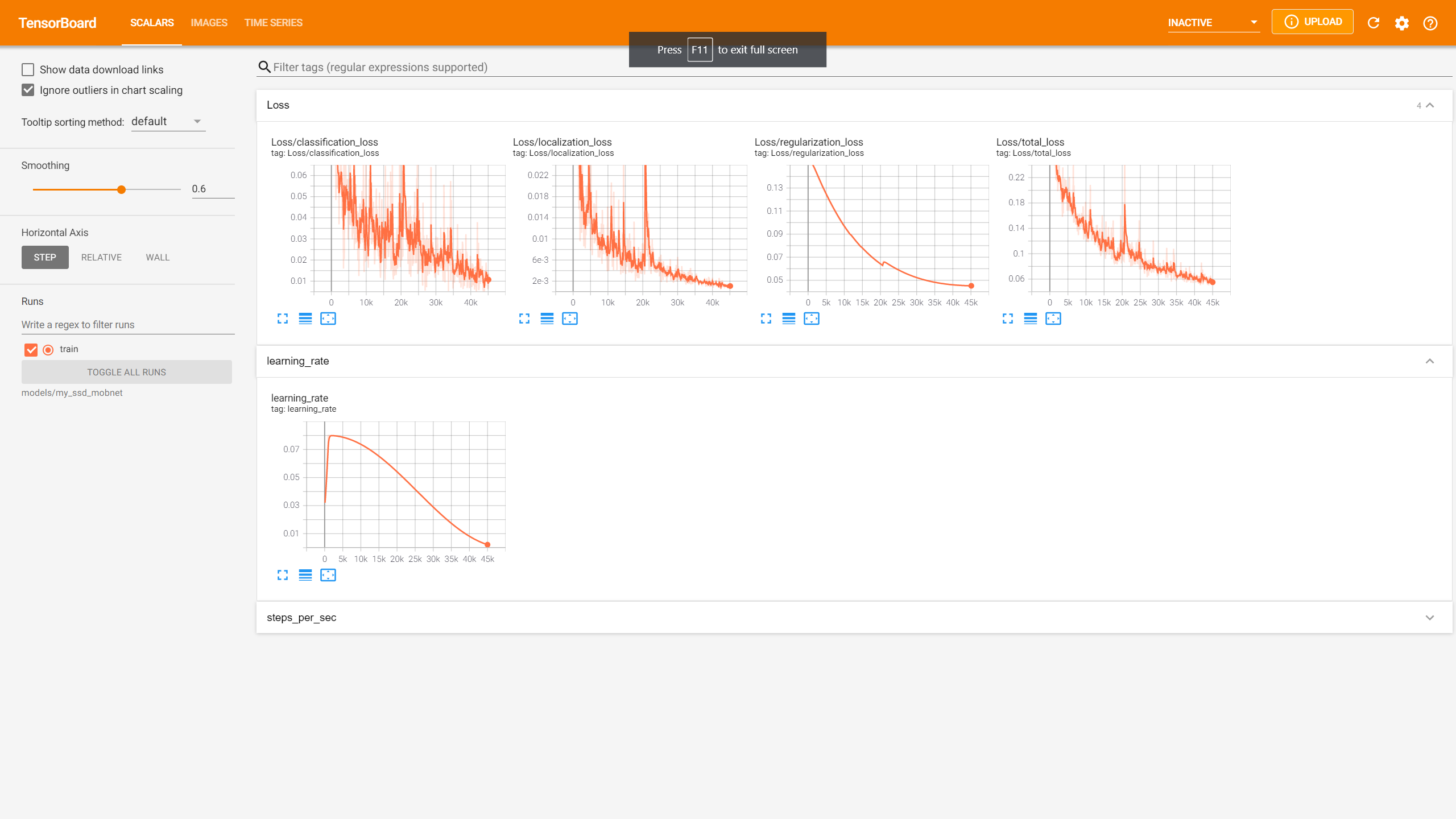
Az alsó képen, szintén a TensorBoard alkalmazás látható, 3-4 óra elteltével. Látható, hogy a 45 ezredik lépésnél tartunk (X tengely). Az Y tengelyről pedig leolvashatjuk, hogy sokkal jobban közelítjük a nullát, mint előzőleg. Az algoritmus végül az 55 ezredik lépésben fejezte be a tanulást. (sajnos képem erről nincs, nem voltam gépközelben)
Miután elkészült az algoritmusunk, nincs más dolgunk, mint hogy számunkra könnyen használható formátumba konvertáljuk. Személy szerint, én a TfLite (TensorFlow Lite) formátumot szeretem, ugyanis kisebb a minimális rendszerkövetelménye, mint egy nyers TensorFlow Mi algoritmusnak. A webes demó elkészítéséhez TfJS (TensorFlow JavaScript) formátumba kellett konvertálnom az algoritmust, ugyanis, csak ezzel a verzióval kivitelezhető egy böngésző alapú, algoritmus futtatás. A konvertálásoknak azonban van egy hátránya: TfJS estén, a konvertálás során az algoritmus le fog lassulni, ugyanis a böngészős alkalmazásokban lehetetlen tartani a pár milliszekundumos észlelési időt. TfLite és a nyers TF algoritmus között minőségbeli vagy gyorsaságbeli különbséget nem tapasztaltam. (A legelső videón a mesterséges intelligenciát, TfLite formátumból futtattam.)
A kész algoritmus demója ide kattintva kipróbálható! (legalább 4 magos, erősebb processszor ajánlott)
Konklúzió
A cikk elején kifejtettem, miért van szükségünk táblafelismerő rendszerekre az autókban, valamint problémáikat. Ezt követően megnéztük, hogy egy mesterséges intelligenciával működő táblafelismerő rendszer azért jobb, mint társai, mivel lényegesen pontosabb és gyorsabb. Majd nagy vonalakban ismertettük, hogy lehet egy ilyen Mi-vel működő rendszert létrehozni. De vajon működik- e, az én rendszerem a valóságban? A következő videó, több videóból összevágott montázs, mely a valódi utakon készült.
A videóból látható, hogy a megadott táblákat a mesterséges intelligencia feismeri. A rendszer természetesen továbbfejlesztésre szorul, hiszen minden közlekedési tábla felismerése a végső cél.
Összességében a rendszer működik. Én nagyon élveztem a kidolgozását, s a jövőben tervezem a továbbfejlesztésén dolgozni, más egyéb, megvalósítani kívánt ötleteim mellett.